MLOps Security Benchmark: Mapping OWASP and MITRE ATLAS Onto a Real ML Pipeline
I’ve been going through an MLOps program over the past few months. Most of the curriculum is about tooling. DVC for data versioning. MLflow for experiment tracking. Feast for feature stores. GitHub Actions for CI/CD. Kubernetes for serving. Evidently for drift. Fairlearn for fairness. Guardrails AI for LLM input validation. All useful, all necessary.
What kept bothering me as I went through it was a different question. Given all these tools, what does a hardened pipeline actually look like? Where does security live? When the course covered prompt injection and adversarial inputs in separate weeks, I noticed nothing pulled them together into a single pipeline-stage threat model. So I started trying to write that consolidation myself.
This post is the result. It maps four published frameworks (OWASP ML Top 10, OWASP LLM Top 10, MITRE ATLAS, NIST AI RMF) onto seven concrete pipeline stages. Then I score two real pipelines I built (one tabular, one LLM) against the same checklist, and I’m honest about where they fall short.
The full benchmark, the reference scripts, and the diagram sources live in a companion repo (MIT licensed).
Why a pipeline-stage view
When someone asks “is your ML pipeline secure?”, most teams reach for a compliance certificate. SOC 2, HIPAA, ISO 27001. The answer is misleading. Those frameworks tell you whether the organization handling the pipeline is secure. They don’t tell you whether your training data has been poisoned last quarter, your model artifact has been swapped at the registry, or your inference endpoint will leak its system prompt to anyone who asks twice.
The published ML-specific frameworks help, but they’re written as threat catalogs. They tell you what can go wrong. They don’t tell you where in your pipeline to put the control. So engineers end up putting the right control at the wrong stage. The most common mistake I see is catching prompt injection at the LLM API but letting the malicious example land in the training set anyway. The control was real. It was just placed too late.
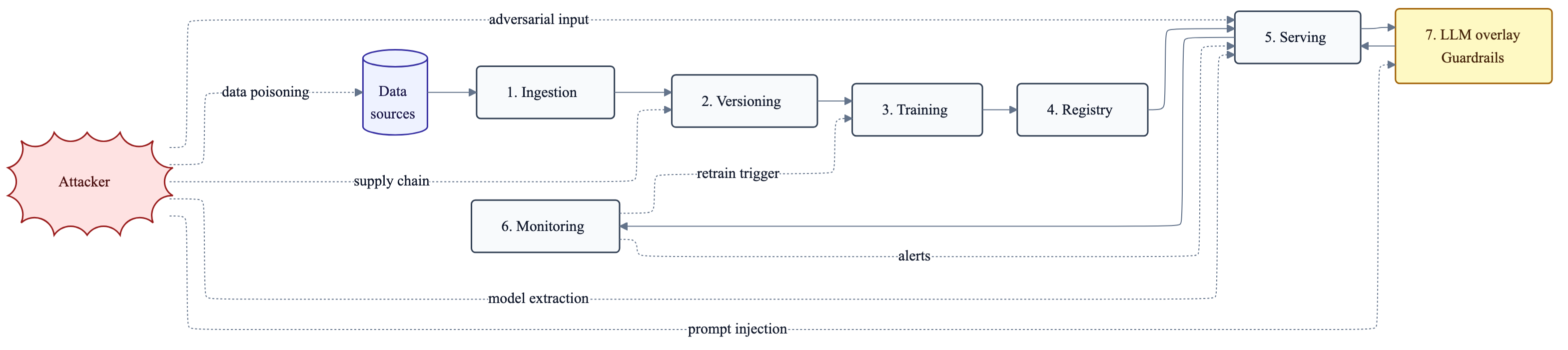
The seven stages
Every ML pipeline I’ve worked on has the same skeleton.
- Ingestion: pulling data from sources (APIs, warehouses, change data capture)
- Versioning: DVC, Git LFS, or object-store snapshots of data and code
- Training: the actual model fit, including hyperparameter tuning
- Registry: where artifacts live before deployment (MLflow Registry, Vertex Model Registry)
- Serving: the inference API, container, autoscaling
- Monitoring: drift, fairness, performance telemetry
- LLM/Generative overlay: prompt management, guardrails, RAG (only if you’re shipping generative models)
Stages 1 through 6 apply to every pipeline. Stage 7 is an overlay that adds new threats on top of the existing six.
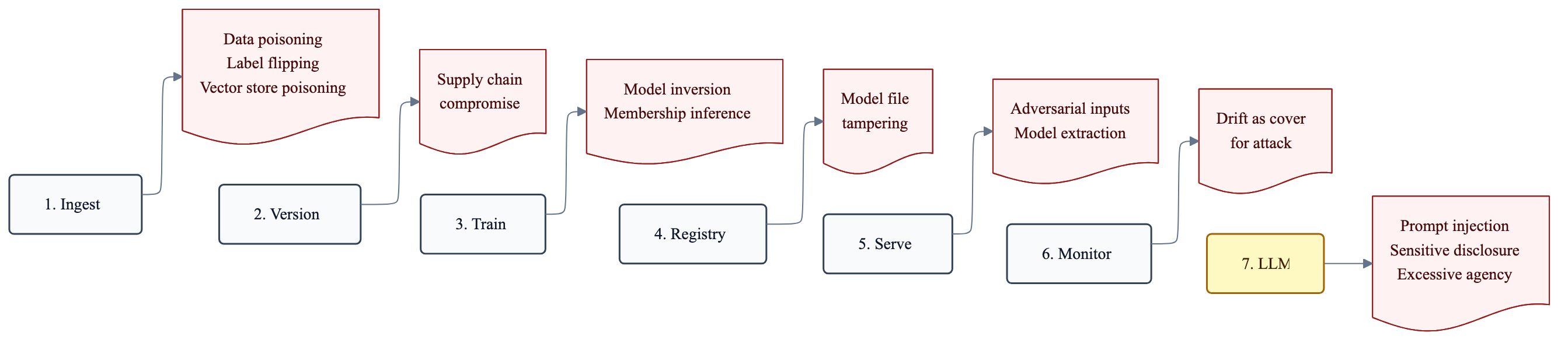
Threat × stage matrix
P = primary control point, S = secondary, blank = not applicable.
| Threat | Ingest | Version | Train | Reg | Serve | Monitor | LLM |
|---|---|---|---|---|---|---|---|
| Data poisoning (OWASP ML02) | P | S | S | ||||
| Label flipping (MITRE ATLAS) | P | S | S | ||||
| Supply chain compromise | S | P | S | S | |||
| Model file tampering | P | S | |||||
| Adversarial inputs (OWASP ML01) | S | P | S | ||||
| Model inversion | P | S | |||||
| Membership inference | P | S | |||||
| Model extraction (theft via API) | P | S | |||||
| Drift used as cover for attack | P | ||||||
| Prompt injection (OWASP LLM01) | S | P | |||||
| Sensitive info disclosure (LLM02) | S | P | |||||
| Excessive agency (LLM06) | P | ||||||
| Vector store poisoning (RAG) | P | S | P |
The pattern is consistent. Most threats have one primary stage and one secondary. If you only put a control at the secondary stage, you’re catching damage already done.
Per-stage controls
Each stage has a checklist. For each control I’ve tried to give a way to actually verify it, not just check a box.
1. Ingestion
| Control | Verify by |
|---|---|
| Source authentication (signed feeds, mTLS, IAM) | Reproduce the connection from a fresh machine without leaked credentials. If it works, your auth is broken. |
| Schema contract enforcement (Great Expectations, Pandera) | Mutate one column type in a test fixture. Ingestion should reject. |
| Class-balance regression test | Track historical class ratios. Alert on > 5% deviation from rolling mean. |
| Outlier rate ceiling | Reject batches with anomaly rate above threshold. Quarantine for review. |
| PII scanner before landing | Detect SSNs, cards, IDs before they hit storage. Google DLP API or Presidio. |
This is the stage where data poisoning is cheapest to defend against. By the time poisoned rows reach training, they’re versioned and you have to retrain to fix them.
2. Versioning
| Control | Verify by |
|---|---|
| Signed Git commits (gitsign, GPG) | Push an unsigned commit. CI should reject. |
| DVC remote with object lock or generation match | Prevents silent overwrite of versioned datasets. |
Hash-pinned Python deps (pip-compile --generate-hashes) |
Tampered wheel fails install. |
| Forensic audit trail | Who pushed which DVC version, when. dvc log plus GitHub audit log retention. |
In one of my pipelines I tracked mlflow.db.dvc and mlruns.dvc against a GCS remote. The remote was authenticated through a service account, but the bucket didn’t have object lock enabled. That’s a gap. With object lock, even a compromised service account can’t rewrite history.
3. Training
| Control | Verify by |
|---|---|
| Hermetic training runs (Docker, fixed base image SHA) | Re-run the same git SHA on a different machine. Get the same metrics. |
| Differential privacy where membership inference matters | Opacus or TF Privacy with a target epsilon. Record epsilon in the model card. |
| Robust training for adversarial examples | Madry-style PGD adversarial training for high-risk models. |
| Training run identity | Every run signed by service account. Logs show which SA produced which artifact. |
| Lineage logged to MLflow | One model = one git SHA + one DVC hash + one container digest. |
4. Registry
| Control | Verify by |
|---|---|
| Signed model artifacts (cosign, sigstore) | Try to deploy an unsigned artifact. CD should refuse. |
| SBOM attached to artifact | Run syft against the registry entry. Get a full dependency list. |
| Model card with security metadata | DP epsilon if used, training data version, fairness audit reference, known limitations. |
| Promotion gate from staging to prod | GitHub environment protection rules. Explicit human approval required. |
| Immutable tags | latest is forbidden in prod. Only digest pins. |
5. Serving
This is where the most controls cluster. It’s the public attack surface.
| Control | Verify by |
|---|---|
| Authenticated endpoint | Hit the endpoint with no key. Should return 401. |
| Rate limiting per principal | Burst test. Verify you get 429s, not 200s. |
| Input schema validation | Send a malformed payload. Expect 400 with no stack trace leaked. |
| Output filtering for PII | Run synthetic input that would echo a PII feature. Ensure it’s redacted. |
| Resource limits, readiness/liveness probes | Pod must restart cleanly under load. Verify with wrk -c 2000. |
| Watermarking for extraction defense | Insert a few canary inputs with known outputs. If they leak through a competitor’s API, you have evidence. |
| Container scanning in CI (Trivy, Grype) | Build a container with a CVE. CI should fail. |
| Least-privilege service accounts | The serving SA should have only roles/aiplatform.user and similar. Not Editor. |
6. Monitoring
| Control | Verify by |
|---|---|
| Drift detection as a security signal | A sudden distribution shift is sometimes adversarial probing. Alert SRE, not just MLE. |
| Right test for the data shape | KS for continuous, Chi-squared for categorical, MMD for high-dimensional embeddings, PSI for binned scoring. |
| Fairness monitoring on production traffic | Re-run Fairlearn MetricFrame on a sliding window of predictions vs. ground truth. |
| Audit logging | Cloud Logging with PII redacted. Retention aligned with GDPR, DPDPA, or nFADP. |
| Anomaly detection on request patterns | Sudden spike from one IP or API key = attack or runaway script. Either way, page someone. |
7. LLM / Generative overlay
When the artifact is a language model, you inherit all of stages 1 through 6 plus a new threat surface.
| Control | Verify by |
|---|---|
| Input guardrail before the model | Regex blocklist + structural Pydantic check. Red-team prompts in CI. Block rate must clear a threshold. |
| Output guardrail after the model | Canary token leakage scan plus format validator. Plant a SECRET_TOKEN in the system prompt. Any output containing it = blocked and alerted. |
| Prompt versioning under git | Every prompt change = PR with diff review. |
| Critique LLM as an optional second pass | Use a smaller model to re-score the primary output before serving for high-risk decisions. |
| Per-tenant rate limits | Prevents cost amplification attacks (jailbreaks that loop). |
| Tracing with cost capture | MLflow 3.x traces. Cost-per-tenant dashboard. Alert on outliers. |
Scoring a heart disease classifier pipeline
To check whether the benchmark is useful in practice, I scored a pipeline I built a while back. It’s an end-to-end heart disease classifier on GCP. Trained with scikit-learn, served from Flask on GKE with HPA, packaged via GitHub Actions CI/CD into Artifact Registry. SHAP for explainability. Fairlearn with age as the sensitive attribute. KS-test for drift. wrk for stress testing.
Here’s how it scores.
| Stage | Score | Notes |
|---|---|---|
| Ingestion | 4/10 | Static CSV. No schema contract, no PII scan. Fine for an internal proof-of-concept, not for prod. |
| Versioning | 6/10 | DVC remote present. Commits unsigned. Deps pinned by version, not by hash. |
| Training | 7/10 | Reproducible (train.py is deterministic with seed). No DP, no adversarial training. Both fine for low-risk tabular data. |
| Registry | 3/10 | Model is rebuilt at container build time. No separate registry, no signing. Real gap. |
| Serving | 7/10 | HPA, readiness probes, IAM. No rate limiting, no API auth. Two real gaps. |
| Monitoring | 6/10 | KS-based drift detection (drift_detection.py), SHAP, Fairlearn. No production sliding window. Drift is computed once. |
| LLM overlay | n/a | Not generative. |
The two changes I’d make first: add API authentication on the serving endpoint (one Kong plugin or one Cloud Endpoints config), and migrate the model to MLflow Registry with signed artifacts so the CI/CD doesn’t bake training into the container build. Both are under a day of work each. Both move the score from “internal demo” to “I’d let it serve real traffic.”
There’s another change worth flagging. The GitHub Actions workflow uses a single GCP_SA_KEY secret with broad GKE plus Artifact Registry roles. The better tier is Workload Identity Federation: no static key on disk anywhere. That migration takes an evening. I’d recommend it for any production pipeline.
Scoring an LLM guardrails project
The second pipeline I scored is a smaller LLM project. Input and output guardrails on top of a Vertex AI gemini-2.5-flash classifier doing IRIS species prediction. Six tasks: red-team prompt injection, red-team prompt leakage, input guardrails, output guardrails, effectiveness measurement, CI regression gate.
The numbers from metrics_v1.json and metrics_v2.json:
| Metric | v1 (specific prompt) | v2 (non-specific prompt) |
|---|---|---|
| Injection block rate | 1.000 | 1.000 |
| Leakage block rate | 1.000 | 0.833 |
| False positive rate (legit holdout) | 0.000 | 0.000 |
| Accuracy delta (guarded - unguarded) | -0.033 | 0.000 |
The LLM overlay scores 8/10. The two I docked: no critique model, no per-tenant rate limit (single-tenant scope, so not directly relevant).
What worked: the input guard is a Pydantic v2 strict schema (extra=forbid on IrisInputV1) plus an 18-pattern regex blocklist. The output guard scans for a planted SECRET_TOKEN, system-prompt shingles, and a few static phrases that should never appear in a flower classification response. Then it validates the output against an IrisOutput Pydantic model. If any check fails, the request gets blocked and the audit logs (audit_input.jsonl, audit_output.jsonl) record the trigger.
What didn’t quite work: v2 leakage block rate is 0.833, not 1.000. The non-specific prompt template (prompt_v2) describes the flower features as natural language instead of passing them as a structured payload with the class list. That gives the LLM more latitude in its response, which sometimes leaks part of the system prompt despite the canary scan. v1 (prompt_v1) is more constrained and blocks 100% of leakage attempts. This is a real, measurable trade-off between prompt flexibility and output security.
What this benchmark is not
It isn’t a replacement for SOC 2, HIPAA, or nFADP. Those still apply. The benchmark sits above them. It’s the layer the compliance frameworks don’t reach into.
It isn’t static. OWASP ML Top 10 and OWASP LLM Top 10 are revised every year. The threat × stage matrix should be regenerated as new threats land.
It isn’t a guarantee. A passing score means the obvious controls are in place. It does not mean you’re safe against a determined attacker. For high-risk deployments (medical, financial, identity verification), pair this with a formal red-team engagement.
Where MLOps curricula could go further
Most MLOps courses teach the tools well. DVC, MLflow, Feast, Kubernetes, Evidently, Fairlearn, Guardrails AI. What’s usually left to students is the synthesis. Given these tools, what does a hardened pipeline actually look like? This benchmark is one possible answer.
Two things that would help:
Threat modeling early in the curriculum, not just in a security-focused module. Security has to be designed in, not bolted on. Asking students to threat-model their pipeline at the start of a project changes what they build by the end of it.
A red-team component in capstone work. Capstone projects already cover explainability, fairness, drift, and stress testing. Adding a security checklist as a deliverable (even a small one: “show three controls from this list and explain how you verified them”) closes a gap that most graduates only hit later, in production.
Reproduce or extend
The full benchmark checklist as a standalone Markdown file, plus reference implementations of the controls, lives in the benchmark repo (MIT licensed). Fork it, score your own pipeline, send back PRs.
Reference implementations included in the repo:
reference/drift_detection.py: KS and Chi-squared drift reportreference/input_guard.py: Pydantic strict schema with an 18-pattern regex blocklistreference/output_guard.py: canary token plus system-prompt shingle leakage scanreference/redteam_runner.py: CI regression gate harnessreference/k8s/deployment.yaml: hardened GKE manifest. Non-root, read-only FS, dropped capabilities.
If you score your own pipeline against this and find gaps in the framework, I’d like to hear about it.