Swiss PII Detection: Benchmarking Apertus-8B and Llama 3.1 8B
In September 2025, the Swiss AI Initiative released Apertus-8B. It was a big deal for Switzerland. EPFL, ETH Zurich, and the Swiss National Supercomputing Centre (CSCS) had teamed up to build the country’s first open-source large language model. 8 billion parameters, trained on 15 trillion tokens across over 1,000 languages, with 40% non-English data. Swiss German. Romansh. French. Italian. The whole range.
The project was built around compliance from the start. The training corpus only used publicly available data, filtered for opt-out requests and personal data removal. The team published everything: architecture, model weights, training code, intermediate checkpoints. Full transparency. They even designed it with Swiss data protection laws and EU AI Act obligations in mind.
We work on AI security tooling for Swiss organizations. A big part of what we do involves filtering personally identifiable information before it gets sent to language models. So when Apertus dropped, we wanted to know: can it actually detect Swiss PII? Not as a theoretical exercise, but as a practical question. If a Swiss company is going to use this model for data protection workflows, what kind of accuracy can they expect?
We built a benchmark to find out. And to put the numbers in context, we ran the same benchmark on Meta’s Llama 3.1 8B Instruct, an established open-weight model of similar size.
The test setup
We put together a dataset of 100 test cases covering Swiss-specific PII types: AHV/OASI numbers, Swiss IBANs, UID company identifiers, VeKa health insurance card numbers, phone numbers, names, addresses, dates of birth, and medical conditions tied to individuals.
All PII values are synthetic. We generated the test cases using Claude Opus with strict requirements that everything follow correct Swiss formats but remain entirely fake. You can’t publish real PII in a benchmark, for obvious reasons.
The tests split into two tasks:
Boolean detection (55 tests): Does this text contain Swiss PII? Yes or no. This is the most basic capability. If a model can’t do this, nothing else matters.
Entity extraction (45 tests): What PII is in this text, and what are the actual values? This is the harder task, but it’s what you’d need for automated redaction or data classification. The 45 extraction tests contained 195 total PII entities, averaging about 4.3 entities per test.
We distributed the tests across five languages:
| Language | Boolean Tests | Extraction Tests | Total |
|---|---|---|---|
| German | 18 | 15 | 33 |
| French | 15 | 12 | 27 |
| Swiss German | 12 | 10 | 22 |
| Italian | 7 | 5 | 12 |
| English | 3 | 3 | 6 |
We included Swiss German dialect on purpose. If you’re processing documents from Switzerland, you will encounter dialect text. We also included 15 “negative” cases: texts that look like they might contain PII but don’t. Things like “The AHV format is 756.XXXX.XXXX.XX” (educational content) or “Zurich has 400,000 inhabitants” (a general fact). Negative cases matter because false positives are a real problem. You don’t want to over-redact harmless content.
For both models, we used structured prompts with LaTeX-style boxing: \boxed{YES} / \boxed{NO} for boolean detection, and \boxed{TYPE: value} for extraction. This gave us deterministic, parseable output.
Apertus-8B was accessed through the public API at api.publicai.co (swiss-ai/apertus-8b-instruct), temperature 0.8 per the developers’ recommendation. The benchmark ran sequentially with a 3-second delay between requests (20 requests/minute rate limit), taking about 13 minutes.
Llama 3.1 8B Instruct was accessed through OpenRouter, temperature 0.1. We ran it with 10 concurrent workers, so the whole thing finished in about 25 seconds.
Overall results
| Metric | Apertus-8B | Llama 3.1 8B |
|---|---|---|
| Overall Score | 73.4% | 93.9% |
| Boolean Accuracy | 74.5% | 94.6% |
| Boolean Precision | 100% | 93.0% |
| Boolean Recall | 65.0% | 100% |
| Boolean F1 | 78.8% | 96.4% |
| Extraction Precision | 99.0% | 95.6% |
| Extraction Recall | 63.6% | 92.0% |
| Extraction F1 | 72.3% | 93.3% |
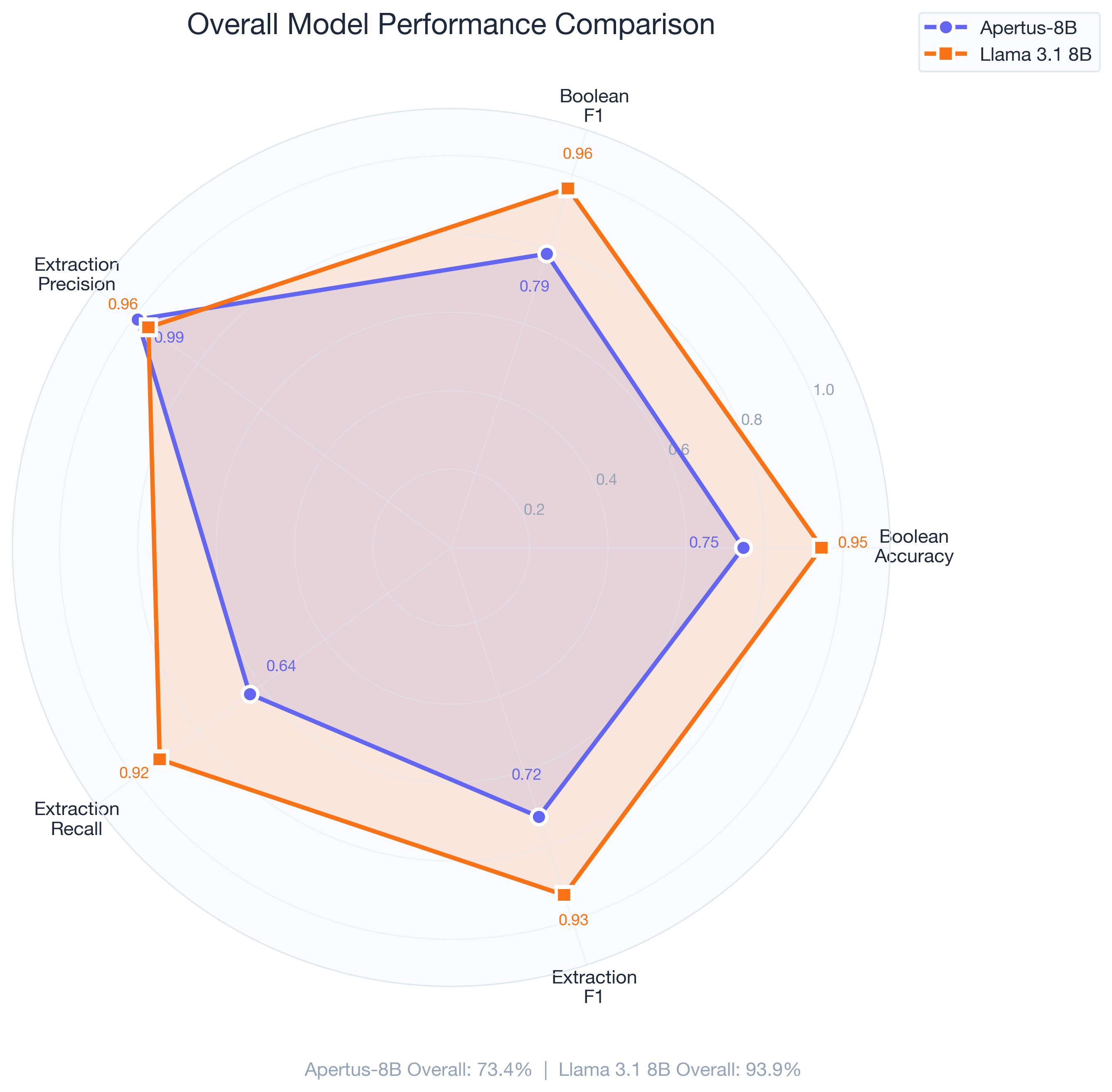
The two models have almost opposite strengths. Apertus is extremely precise. When it says a text contains PII, it’s almost always right (100% boolean precision, 99% extraction precision). But it misses a lot. 35% of texts with PII get classified as clean. 36% of PII entities in extraction tests go undetected.
Llama goes the other way. It catches almost everything (100% boolean recall, 92% extraction recall), but occasionally flags things that aren’t PII (93% boolean precision). In practice, the tradeoff favors Llama’s approach. Missing PII is a compliance risk. Flagging something that’s borderline is just extra review.
Language breakdown
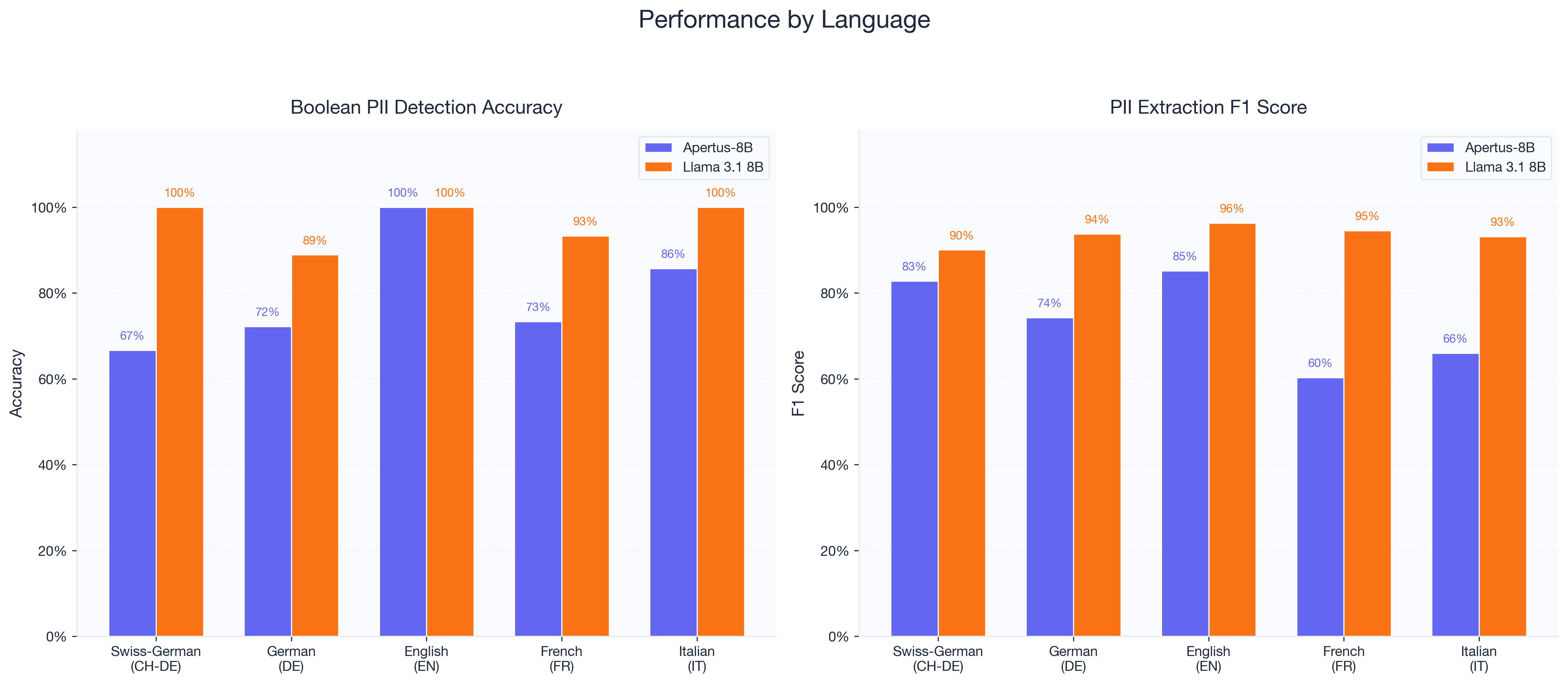
| Language | Apertus Bool Acc | Llama Bool Acc | Apertus Extr F1 | Llama Extr F1 |
|---|---|---|---|---|
| English | 100% | 100% | 85.2% | 96.3% |
| Italian | 85.7% | 100% | 66.0% | 93.1% |
| German | 72.2% | 88.9% | 74.3% | 93.8% |
| French | 73.3% | 93.3% | 60.3% | 94.5% |
| Swiss German | 66.7% | 100% | 82.8% | 90.0% |
Both models handle English well. The gaps show up in other languages.
Apertus’s weakest boolean detection is Swiss German at 66.7%, which is surprising given that Swiss German support was one of the model’s selling points. The extraction score for Swiss German is much better at 82.8%, though. We think this is a prompt sensitivity issue. The boolean prompt asks for a judgment call about whether dialect text “contains” PII. The extraction prompt asks for specific entities, which is less ambiguous. If you’re using Apertus with Swiss German content, extraction-style prompts work better.
French is another weak spot for Apertus, especially in extraction. 60.3% F1 is the lowest of any language. Llama scores 94.5% on the same French tests.
Llama’s worst boolean result is German at 88.9%. Its worst extraction result is Swiss German at 90.0%. Both are still well above all of Apertus’s scores.
Category breakdown
This is where things get interesting.
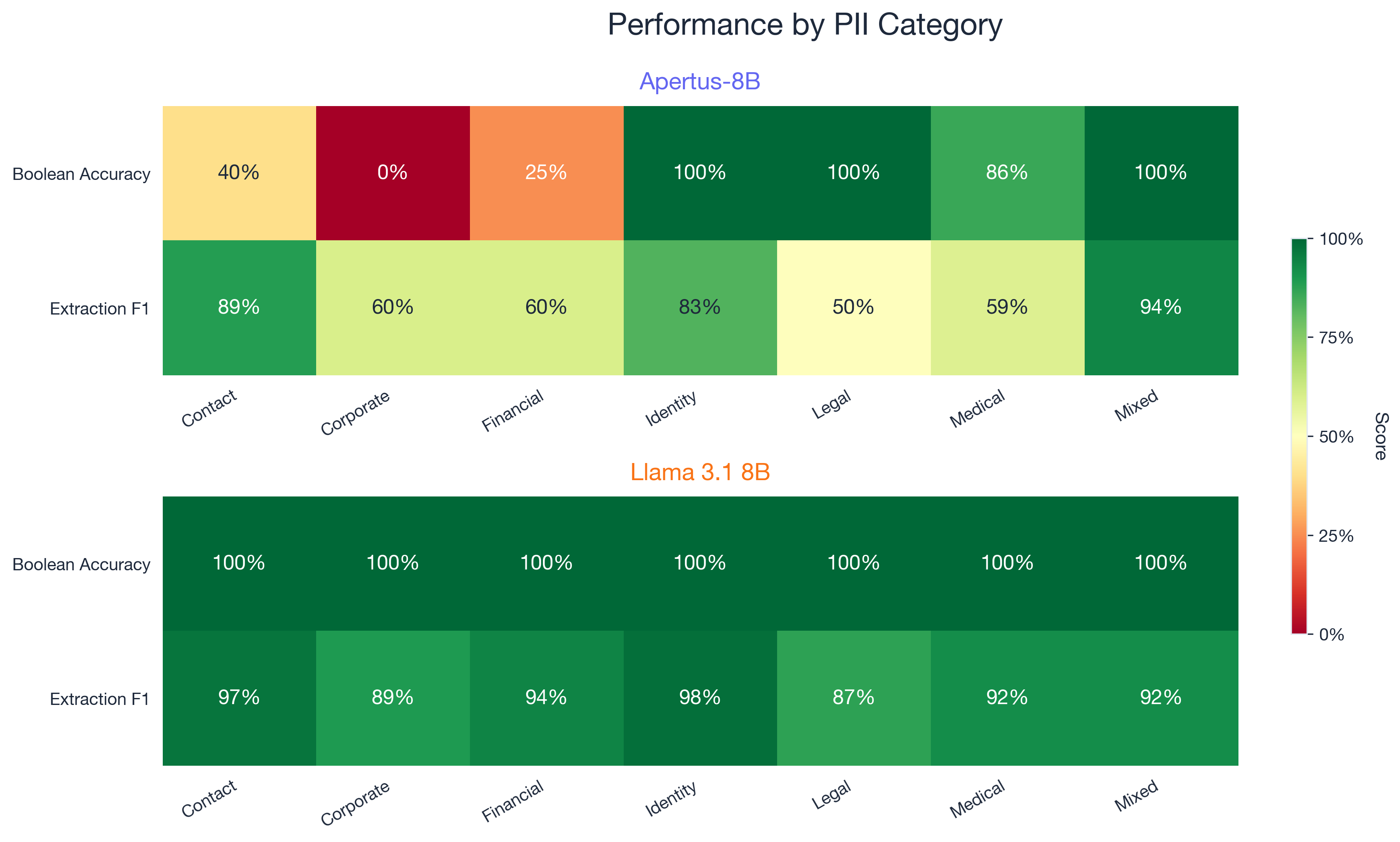
| Category | Apertus Bool | Llama Bool | Apertus Extr F1 | Llama Extr F1 |
|---|---|---|---|---|
| Negative (no PII) | 100% | 80% | n/a | n/a |
| Identity | 100% | 100% | 82.6% | 97.5% |
| Mixed PII | 100% | 100% | 93.6% | 92.0% |
| Legal | 100% | 100% | 50.0% | 86.7% |
| Medical | 85.7% | 100% | 58.9% | 91.7% |
| Contact | 40.0% | 100% | 88.6% | 97.2% |
| Financial | 25.0% | 100% | 60.0% | 94.4% |
| Corporate | 0% | 100% | 60.0% | 88.9% |
Apertus scored 0% on corporate boolean detection. That means it failed to detect PII in every single business document we tested. Names in formal business correspondence, UIDs in company communications, that kind of thing. Financial detection at 25% is nearly as bad. These are high-risk categories. If you’re a Swiss bank or insurance company screening customer communications, these are exactly the documents you need to process.
On the positive side, Apertus hit 100% on negative cases, meaning it never falsely flagged educational or factual content as containing PII. Llama was less careful here, scoring 80% on negatives (three false positives out of fifteen). And Apertus’s mixed PII extraction at 93.6% F1 is actually slightly better than Llama’s 92.0%. Documents that contain multiple PII types, like medical records or insurance claims, are handled well.
Llama got 100% boolean accuracy on every category except negatives. Its extraction scores were consistently above 86% across all categories.
Precision vs. recall tradeoff
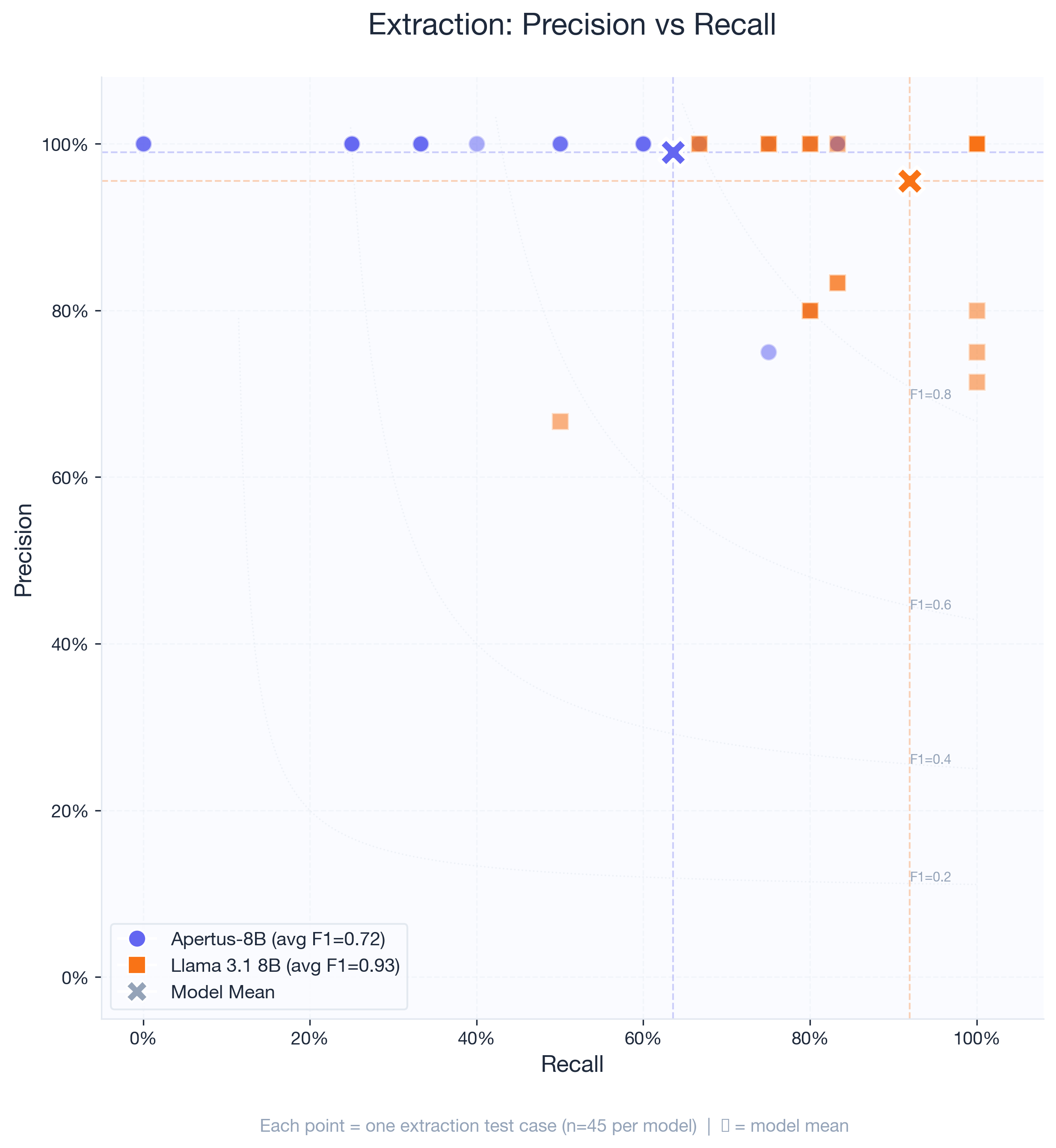
The scatter plot makes the difference visible. Apertus tends to sit along the top of the chart (high precision, variable recall). Llama clusters in the upper-right corner (high precision and high recall).
When Apertus does extract entities, it’s almost always correct. But there are entire categories of PII it simply doesn’t catch, especially in longer texts where PII is embedded in transactional or business language rather than clear data fields.
Llama occasionally produces false extractions (precision dips to 67-80% on a few tests), but it rarely misses actual PII.
What does this mean for compliance?
Under the Swiss Federal Act on Data Protection (nFADP), Article 8 requires “appropriate technical and organizational measures” for data security. The GDPR has similar requirements in Article 32.
A 65% recall rate (Apertus) means about a third of personal data goes undetected. Traditional rule-based PII detection (regex matching for AHV numbers, IBANs, emails) typically hits 80-95% recall on structured patterns. It’s not smart enough to catch unstructured PII like names and addresses, but for formatted identifiers, it works reliably. Apertus’s 65% recall falls below that baseline.
Llama’s 92% extraction recall is more practical. You’d still want human review for anything compliance-sensitive, but the volume of missed PII is much smaller.
An argument in Apertus’s favor: the 100% precision on negative cases means it won’t cause problems in documentation or policy text. If your use case is pre-filtering before human review, and you’d rather miss some PII than create false alarms, that tradeoff might work.
Suggestions for the Apertus team
The Swiss AI Initiative built something ambitious. A fully open, multilingual model with compliance built in from day one. That’s a real contribution to the ecosystem. Based on our results, a few areas that could improve PII detection performance:
Corporate and financial training data. The 0% and 25% boolean detection rates in these categories suggest they’re underrepresented in training. These are the highest-risk categories for Swiss data protection, so addressing them would go a long way.
Recall tuning. The model is too conservative. It knows when it’s uncertain and defaults to “no PII found,” which explains the perfect precision but low recall. For compliance applications, trading some precision for higher recall would be a worthwhile adjustment.
Swiss German consistency. The gap between boolean detection (66.7%) and extraction (82.8%) on Swiss German content suggests something is off with how the model processes dialect in different prompt formats. Alignment training on dialect content could help close this.
French performance. 60.3% extraction F1 is the weakest score across any language. Given that French is one of Switzerland’s four national languages, this should get attention.
Why we ran this benchmark
We’re building NativeAI Guard, a security layer that filters sensitive data from queries sent to language models. Testing how well different models detect Swiss PII directly informs the design of our filtering pipeline. We need to know which models catch what, where the blind spots are, and what kind of fallback detection is necessary.
The test dataset and benchmark scripts are open for anyone who wants to reproduce or extend this work.
Summary
Apertus-8B gets 73.4% overall on Swiss PII detection. Llama 3.1 8B Instruct gets 93.9%. Both are 8 billion parameter models.
Apertus is characterized by exceptional precision and poor recall. It almost never makes false claims, but it misses a third of the PII it should find. It struggles with corporate, financial, and contact information categories, and its weakest languages are Swiss German (boolean) and French (extraction).
Llama catches more PII across the board but is slightly less careful with negatives (80% vs 100% on texts that don’t contain PII).
For PII detection specifically, Llama is the stronger model at this scale. But Apertus wasn’t designed primarily for PII detection, and the Swiss AI Initiative has stated that domain-specific adaptations (including law and health) are on the roadmap. A future version fine-tuned for data protection could change these numbers significantly.
We plan to run follow-up benchmarks when the Apertus team releases updated versions, and we’ll test the 70B variant as well. We’re also interested in comparing both models against traditional rule-based detection to quantify where LLM-based PII detection adds value over regex patterns.
The test dataset and benchmark scripts are available for others to build on. If you’re working on PII detection for Swiss contexts and want to discuss methodology, we’d like to hear from you.